2 yıl önce giriştiğim ama daha sonra peşini bıraktığım, okuduğum kitapların listesini tutmak için oluşturduğum kitaplar sitesini tekrar devreye aldım. Sorun şu ki öncesinde pek fazla içerik eklememiştim ve şimdi eskiye nazaran daha fazla içerik oluşmuştu.
Okuduğum kitapların listesini bir süre Goodreads’te tutmaya çalıştım, arayüzü çok kıytırık ve aşırı yoğun geldiği için bir süre sonra kullanmamaya başladım. Daha sonra Türk alternatif 1000Kitap’ı buldum ve 2015 yılında onu kullanmaya başladım (bir kaç tane aklıma gelen kitap ekledim diyelim). Daha sonra onu da bir süre kullanmadım fakat 2018’de düzenli bir şekilde kullanmaya başladım. İşin özü düzenli olarak tuttuğum liste orada olduğu için yeni siteye ekleyeceğim kitapların listesini oradan almam gerekiyordu. Sadece okuduğum kitapları ekleyecek olsam altı üstü 125 tane kitap var, tek tek elle girebilirim fakat bunların yanında eklediğim alıntılar da var ve bunların sayısı 864. Yani tek tek elle girmeme imkan yok. Bunun için hızlıca siteden verileri çekebilmem gerekiyordu. Ne yazık ki 1000K’da verileri indirme gibi bir seçenek yok.
Bu noktada Web Scrapper’ı buldum. Tarayıcı eklentisi olarak çalışıyor. Chrome (ve Chromium tabanlı tarayıcılar) ve Firefox için eklentiler mevcut.
Web Scrapper eklentisini kurduktan sonra Firefox için F12 veya Ctrl+Shift+I (Chrome için de aynı tuş kombinasyonu geçerli) ile geliştirici seçeneklerini (Developer Tools) açmanız ve Web Scrapper sekmesine geçmeniz gerekiyor.

Şimdi verileri çekeceğimiz site için bir sitemap oluşturmamız gerekiyor. Menüden “ Create new sitemap ” > “ Create Sitemap ” seçeneğini seçiyoruz. Sitemap name kısmına herhangi bir isim verebilirsiniz fakat Start URL kısmına kazıyacağımız sayfanın linkini eklememiz gerekiyor.
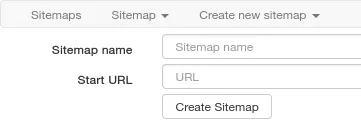
Ekledikten sonra sayfada kazınacak bölümleri ekleyeceğimiz kısım geliyor. Buraya daha sonra “ Sitemaps ” menüsünden isim verdiğimiz sitemaps i seçerek de ulaşabiliriz. Burada “ Add new selector ” butonuna basıyoruz. “ ID ”, “ Type ”, “ Selector ” gibi seçenekler çıkıyor. “ ID ” kısmına tanımlayıcı bir isim vermelisiniz. “ Type ” kısmında seçeceğimiz alanın türünü belirliyoruz. Bunları açıklamak gerekirse;
| Type | Açıklaması |
|---|---|
| Text | Metin seçimi için |
| Link | Bağlantı yolları için |
| Sitemap.xml links | Sitedeki tüm linkleri sitemap.xml’den çekmek için |
| Popup link | Aynı Link gibi fakat yeni pencere açan bağlantılar için |
| Image | Resim bağlantı yollarını seçmek için |
| Table | Tablo Seçimi için |
| Element attribute | Bir HTML öğesinin değerlerini çekmek için |
| HTML | Seçilen öğenin içindeki HTML ve metinleri çekmek için |
| Grouped | Bir çok öğeden tek bir grup olarak (json formatında) metin çekmek için |
| Element | Birden çok veri içeren öğeleri seçmek için |
| Element scroll down | Kaydırdıkça yüklenen sayfalardaki öğeleri seçmek için |
| Element click | Sayfanın yüklenmesi için tıklama gereken sayfalarda öğe seçmek için |
Hepsini tek tek detaylı anlatma şansım yok, kurcalamak gerekiyor ben sadece “ Element scroll down ”, “ Text ” ve “ Image ” türlerini anlatacağım çünkü kullandıklarım onlar.
ID kısmına bir isim verdikten ve türü seçtikten sonra kazıyacağımız alanı belirlememiz gerekiyor. 1000K sitesi kaydırdıkça yüklenen bir site olmasından ve seçeceğim bölümün birden fazla bilgi içermesinden dolayı ilk kullandığım tür “ Element scroll down ” olacak. “ Selector ” bölümünden “ Select ” butonuna basarak seçim yapmayı aktif hale getiriyoruz ve ilgili bölüme tıklıyoruz. Eklenti ilgili bölümü işaretleyerek bize id ’sini veya class ’ını belirliyor fakat her zaman doğru olanı seçemeyebiliyor, bundan dolayı kendiniz bulmanız gerekebilir. Örneğin 1000K’da gönderileri li[data-id:'123123'] şeklinde gösteriyor ki bu yanlış ve içerisinde data-id bulunmasından dolayı tüm gönderileri değil tek bir gönderiyi hedef almış oluyor. Doğrusu .kitap.butonlu olması gerekiyordu. Hatalı olanları elle düzeltmek gerekiyor “ Done selecting ” dedikten sonra. Sonrasında hedef tek mi yoksa bu hedeften birden fazla mı var onu belirlemek gerekiyor. Eğer tek bir hedef varsa aslında kazımaya da gerek yok ama “ Multiple ” seçeneğini seçmiyoruz. Eğer birden fazla seçenek varsa ki yüzlerce seçenek olduğu için benim durumum bu, “ Multiple ” seçeneğini aktif hâle getirmemiz gerekiyor.
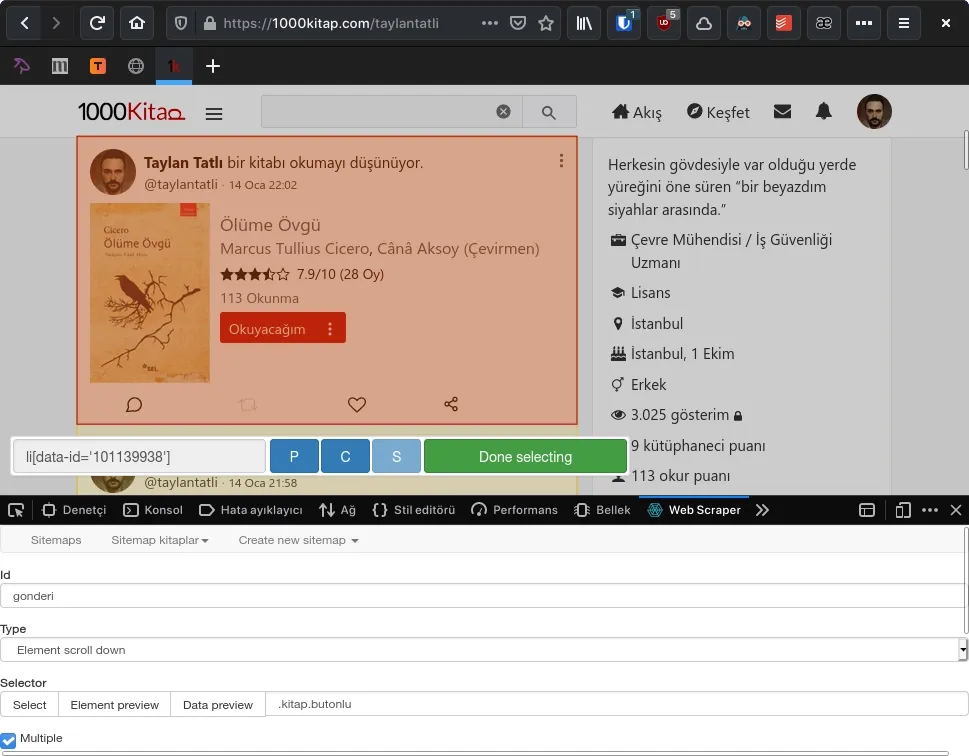
Seçimlerimizi yaptıktan sonra test etmek amaçlı “ Element preview ” tuşuna basabiliriz. Eğer her şey doğruysa ayarladığımız gibi tüm seçenekleri işaretlemesi gerekiyor. Bunların yanında “ Element scroll down ” ile gelen bir seçenek daha var, o da “ Delay ”. Bununla kaydırma gecikmesini mili saniye cinsinden belirliyoruz. Varsayılan ayar 2000 fakat yüklenme uzun sürüyorsa artırılabilir.
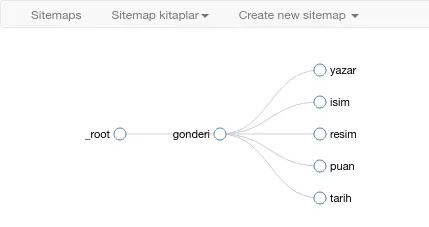
Son seçenek de “ Parent selectors ”. Burada yaptığımız seçimin başka bir seçimin bir altı mı yoksa tepede mi duruyor bunu belirliyoruz. İlk seçimim birden fazla bilgi içeriyordu ve diğer yapacağım seçimler de buna göre belirlenecekti. Dolayısıyla bu yaptığım ilk ayar en tepede yani _root’ta olması gerekiyor. “ Save selector ” diyerek bu ilk ayarımızı kaydediyoruz.
Daha sonra bu elementten verileri çekmeye başlayabiliriz. İlk seçenek gönderinin kedisiydi. Şimdi bu gönderiden kitap adı , yazar adı , kitap kapağı , ne zaman okundu ve kaç puan verildi gibi bilgileri çekmeye başlayabiliriz. Kitap kapağı için “ Image ” türünü diğerleri için de “ Text ” türünü kullanıyorum. Her şey yaptığımız ilk seçimle aynı. Tek fark bu seferkileri _root altına değil bir önceki belirlediğimiz ID altına koymamız gerekiyor ki bu ID ’deki bilgileri çeksin ve de “ Multiple ” seçeneğini aktif etmiyoruz. Ben multiple seçeneğini alt öğeler için de aktif ettiğimden uzun süre kazıma işlemini beceremedim ama sonuçta bir elementten sadece bir veri çektiğimiz için multiple değil tek seçim yapmam gerekiyordu. Çoklu seçim yaptığımız sadece gönderilerdi ve bu gönderilerden de sadece tek bir bilgi çekiyoruz.
Tüm her şeyi ayarladıktan sonra haritayı “ Sitemap verdiğiniz sitemap adı ” menüsünden “ Selector graph “‘e girerek görebiliriz.
Son olarak kazıma işlemini başlatmak kaldı. “ Sitemap verdiğiniz sitemap adı ” menüsünden “ Scrape ” seçeneğine tıklıyoruz. Burada başlamadan önce mili saniye cinsinden “ Request interval (istek aralığı)” ve “ Page load delay (sayfa yükleme gecikmesi)” seçenekleriniz ayarlamamız gerekiyor. Başlangıç için olduğu gibi bırakabiliriz, eğer sorun yaşanırsa bu süreler artırılabilir. “ Start scraping ” tuşuna basarak kazıma işlemini başlatıyoruz. Eklenti sitenin bağlantısını yeni pencerede açacak ve eğer kaydırmalı bir tür varsa tüm sayfayı kaydırarak eğer yoksa da açılan sayfadaki tüm bilgileri olduğu gibi çekip pencereyi kapatacaktır.
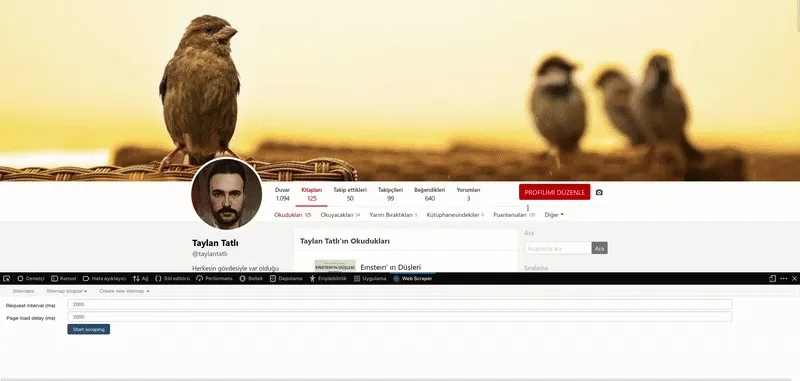
Ekran kapandığında sonuçlar görünmezse “ Refresh ” tuşuna basarak yenileyebilirsiniz ya da “ Sitemap verdiğiniz sitemap adı ” menüsünden “ Browse ” seçeneğine basabilirsiniz. Çektiği tüm bilgileri tablo halinde karşınıza getirecektir. “ Sitemap verdiğiniz sitemap adı ” menüsünden “ Export data as CSV ” seçeneğini seçerek tablo dosyası olarak bilgisayarınız indirebilirsiniz.

Bu oluşturduğunuz sitemap tarayıcınızda saklanacak ama yedeklemek isterseniz “ Sitemap verdiğiniz sitemap adı ” menüsünden “ Export Sitemap ” seçeneğini seçerek açılan ekrandan Json formatındaki kodu alıp yedekleyebilirsiniz. Bunu daha sonra “ Create new sitemap ” menüsünden “ Import sitemap ” diyerek kullanabilirsiniz. 1000K için kullandığım sitemap şu şekilde:
{ "_id": "kitaplar", "startUrl": ["https://1000kitap.com/taylantatli/kitaplari/okuduklari"], "selectors": [ { "id": "gonderi", "type": "SelectorElementScroll", "parentSelectors": ["_root"], "selector": ".kitap.butonlu", "multiple": true, "delay": "3000" }, { "id": "yazar", "type": "SelectorText", "parentSelectors": ["gonderi"], "selector": "div.bilgi:nth-of-type(4) a:nth-of-type(1)", "multiple": false, "regex": "", "delay": 0 }, { "id": "isim", "type": "SelectorText", "parentSelectors": ["gonderi"], "selector": ".baslik a", "multiple": false, "regex": "", "delay": 0 }, { "id": "resim", "type": "SelectorImage", "parentSelectors": ["gonderi"], "selector": ".resim > a > img", "multiple": false, "delay": 0 }, { "id": "puan", "type": "SelectorText", "parentSelectors": ["gonderi"], "selector": "div.ekBilgi", "multiple": false, "regex": "([^\\s]+)/([^\\s]+) puan", "delay": 0 }, { "id": "tarih", "type": "SelectorText", "parentSelectors": ["gonderi"], "selector": ".ekBilgi a", "multiple": false, "regex": "", "delay": 0 } ]}Puan kısmı için regex kullandım fakat regex işine burada girersem sonunu getiremem, kaldı ki ben de çoğu şey için sürekli İnternet’e bakmak durumunda kalıyorum.
Son olarak burada yazılanlar bilgi amaçlıdır, anlatımımın mükemmel olduğunu düşünmüyorum bundan dolayı gerçekten kullanabilmek için kendinizin kurcalaması gerekiyor (benim yaptığım gibi). 👨💻